

○○県○○市○○○丁目・・・
こんな住所データを、都道府県・市区町村・残りの住所のように分割したいときに使える関数、
REGEXEXTRACT関数の使い方を解説します。
何かと応用の利く関数なので、図解付きでわかりやすく解説していきますね。
REGEXEXTRAT関数の書式
REGEXEXTRACT関数の書式は以下の通りです。
=REGEXEXTRACT(テキスト,正規表現)
「テキスト」は分割したい文字列の入っているセル番地を入れます。
ややこしく思えるのは「正規表現」
「?」「*」くらいしか使ったことのない人には難しく感じるかもしれません。
ここでは、実際に住所を分割する例を交えながら、REGEXEXTRACT関数の書き方(特に正規表現について)を解説していきます。
一般的な正規表現について以下の記事でも簡単にまとめています。

REGEXEXTRAT関数を使って都道府県のみ抽出する
下図の表を例に、住所の文字列を都道府県・市区町村・残りの住所(住所1)の3つに分けていきたいと思います。
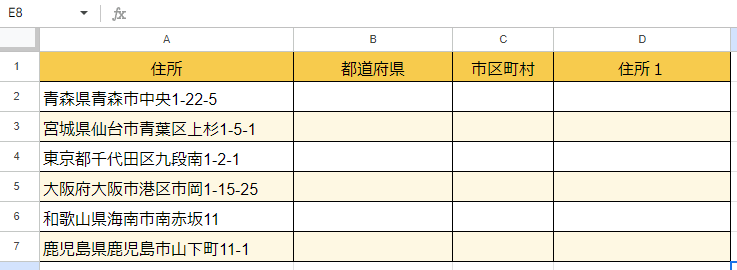
結論から言うと、このような結果にしたいということです。
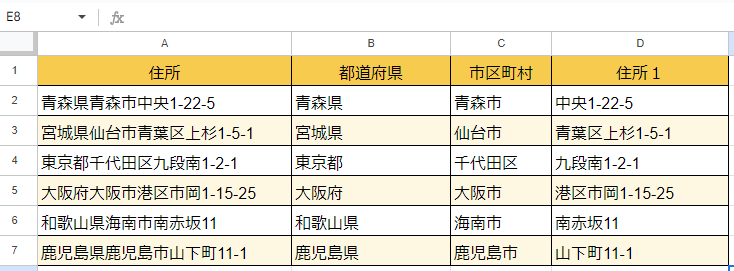
REGEXEXTRACT関数を使うことであっという間にできてしまいます。
早速ですが、セルB2に次の式を入れてみます。
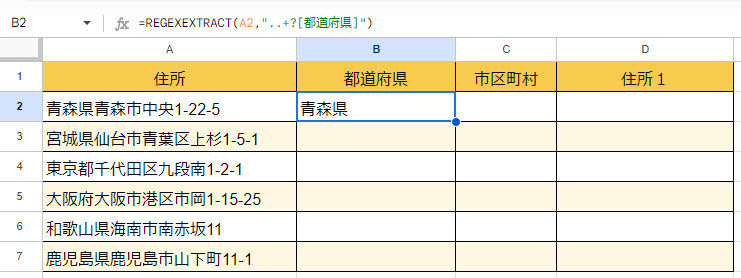
=REGEXEXTRACT(A2,”..+?[都道府県]”)
するとこのような結果になります。見事に県名だけ抜けていますね。
関数の書式は、
=REGEXEXTRACT(テキスト,正規表現)
ですので、
「テキスト」の部分は住所の入っているセルA2を指しています。
「正規表現」の部分が ” ..+?[都道府県] ”
正規表現は、必ず””(ダブルクォーテーション)で括ってください。
暗号のようにも見えますが、一文字ずつ説明すると、
. ピリオドは「任意の1文字」
+ プラスは「直前の文字を1回以上繰り返す文字」
? クエスチョンは「直前の文字を0か1回繰り返す文字」
[都道府県] 都・道・府・県のいずれか1文字と一致
都道府県名は必ず3,4文字です。(都道府県も含んだ文字数)
さらに、都道府県名のあとに出てくる住所に都道府県の文字あって該当してしまうと困ります。
なので、このような正規表現になるのです。
市区町村も抽出してみる
このままでは、都道府県しか抽出できていないので、市区町村以下も抜き出していきます。
REGEXEXTRACT関数の正規表現の部分は、 () でくくることで複数指定することができます。
今度はセルB2に以下の式を入れてみましょう。
=REGEXEXTRACT(A2,”(..+?[都道府県])(.+?[市区町村])”)
最初の書き方を参考に、都道府県の部分を () でくくり、新たに[市区町村]を () でくくって並記しています。
結果は下図のようになります。
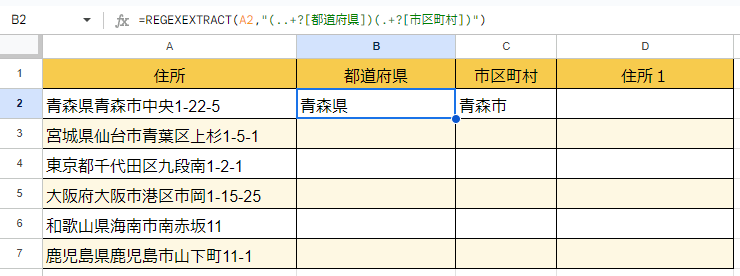
勝手にC列に市区町村に該当する部分が入っていますね。
このように、 () でくくることで複数の条件を指定することができます。
せっかくなのでB2セルをコピーして、B3~B7セルにも反映させてみましょう。
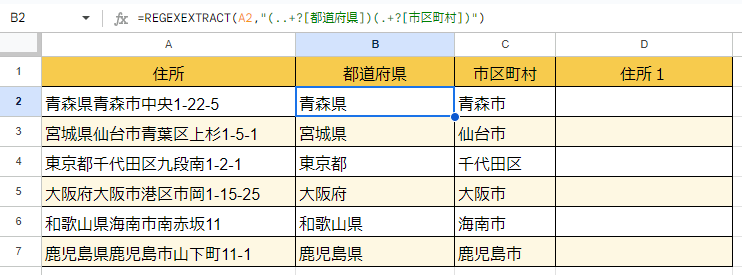
なかなか良い感じです。
C列に値が入っていると、市区町村の値が抽出されずエラーとなるので注意してください。
その他住所も抽出する
最後に、市区町村以下の住所も抽出していきます。
この部分は特に何の指定も(決まった文字があるわけでは無い)無いので、
「残りは全て」とい意味になる正規表現を3つ目の () として追加すると良いです。
式は以下の通り。
=REGEXEXTRACT(A2,”(..+?[都道府県])(.+?[市区町村])(.*)”)
市区町村の後に3つ目の () として (.*) を入れています。
任意の1文字以上全てという意味になります。
入力した結果は下図のようになります。
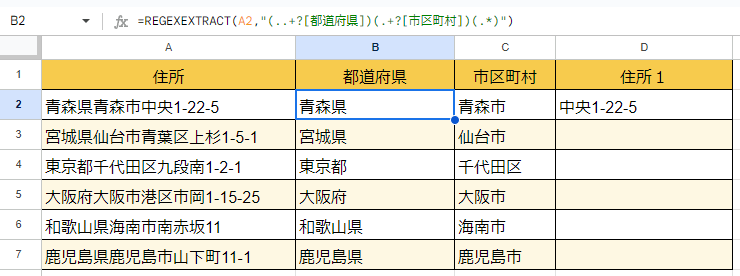
これで、もともとあった住所を、都道府県・市区町村・残りの住所の3つに分割できました。
3行目以降にもセルB2の式をコピーしましょう。
まとめ
以上がREGEXEXTRACT関数の使い方になります。
具体的な例として、住所の分割としましたが、文字数が定まっていないけど、ある程度固定された文字があるようなパターンではとても役立つ関数です。
正規表現の勉強にもなるので、「?」や「+」を付けなかったらどうなるのか?
など実験的に試しながら覚えると、他の関数を使うときにも役立つので、そのきっかけになれば幸いです。


コメント